In the world of ride-sharing and food delivery, every millisecond counts. Uber, a global leader in these domains, operates at an unprecedented scale, handling millions of requests per second. To deliver a seamless and instant experience to its users, efficient data access is paramount. This is where CacheFront, Uber’s ingenious caching (Uber Caching) solution built upon Redis, steps in.
Before CacheFront, Uber faced a classic dilemma: how to handle incredibly high read throughput without incurring prohibitive costs or operational complexities. While their in-house distributed database, Docstore (backed by NVMe SSDs), offered impressive performance, direct usage for every high-read scenario was simply not sustainable. Many teams had resorted to implementing their own Redis caches, but this led to fragmented solutions, inconsistent invalidation logic, and headaches during region failovers.
The Genesis of CacheFront: A Centralized Caching Powerhouse
Recognizing these challenges, Uber’s engineering teams embarked on a mission to centralize and optimize their caching infrastructure. Their answer was CacheFront. The core idea behind CacheFront was to abstract away the complexities of caching, allowing individual microservices to focus on their core business logic while benefiting from a robust, centrally managed caching layer.
Seamless Integration with Docstore’s Query Engine
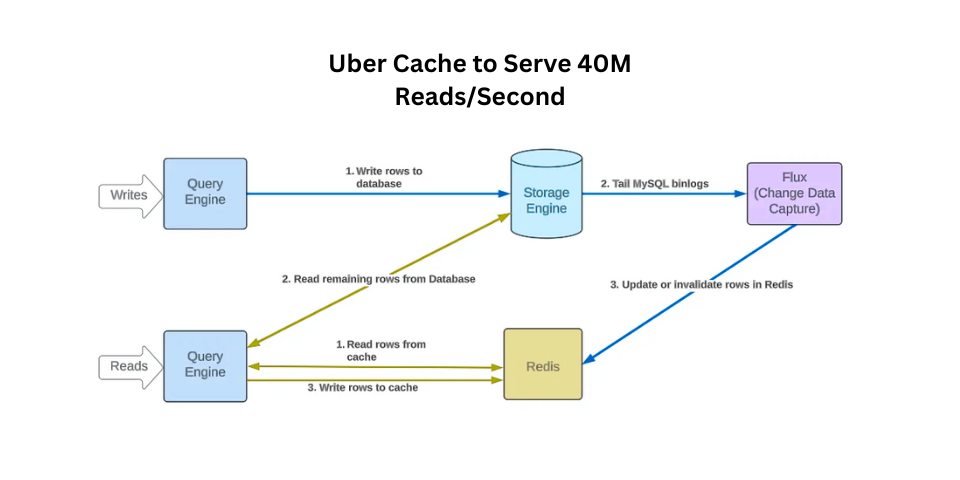
CacheFront isn’t a standalone entity; it’s deeply integrated into Docstore’s query engine. This engine, a stateless frontend to a MySQL-based storage engine, became the perfect conduit for CacheFront. This integration allowed Uber to:
- Scale caching independently: Redis caching could be scaled up or down based on read demand without impacting the underlying storage engine.
- Maintain API compatibility: Existing Docstore APIs continued to work seamlessly, minimizing disruption for development teams.
The Cache-Aside Strategy: Smart Data Retrieval
CacheFront employs a classic yet highly effective cache-aside strategy for read operations. Here’s how it works:
- First Check the Cache: When a read request arrives, the query engine first checks if the data is present in Redis (if caching is enabled for that request).
- Instant Gratification (Cache Hit): If the data is found in the cache, it’s immediately streamed back to the user, providing a lightning-fast response.
- Database Fallback (Cache Miss): If the data isn’t in the cache (a “cache miss”), the query engine fetches the required rows from the Docstore storage engine.
- Asynchronous Cache Population: Crucially, while the data is being streamed from the database to the user, CacheFront asynchronously populates Redis with these newly retrieved rows. This ensures that subsequent requests for the same data will be served directly from the cache.
Real-time Consistency with Change Data Capture (CDC)
Maintaining data consistency between the cache and the database is a critical challenge in any caching system. Uber’s engineers solved this elegantly by leveraging Docstore’s integrated Change Data Capture (CDC) engine.
Instead of relying solely on Time-to-Live (TTL) mechanisms (which can lead to stale data being served for minutes), the CDC engine actively monitors database updates. When a change is detected:
- The corresponding row in Redis is either updated or invalidated.
- This ensures that the cache is consistent with the database within seconds of a change, significantly faster than TTL-based approaches.
- Furthermore, using CDC prevents uncommitted transactions from writing stale data into the cache, guaranteeing data integrity.
Proving Consistency: The “Shadowing” Mode
To validate the effectiveness of their CDC-driven invalidation, Uber implemented a special “shadowing” mode. In this mode, read requests are simultaneously sent to both the cache and the database. The system then compares the retrieved data. Any discrepancies are logged and emitted as metrics, providing real-time insights into cache consistency. Through this rigorous testing, Uber measured their CacheFront system to be an impressive 99.99% consistent.
Active-Active Deployment and Intelligent Cache Warming
Uber operates an active-active deployment across multiple regions to ensure high availability and disaster recovery. Maintaining “warm” caches during region failovers is crucial to avoid latency spikes. CacheFront addresses this by:
- Replicating Row Keys: Instead of replicating entire Redis values (which would be inefficient), CacheFront replicates only the row keys from the Redis write stream in one region to the remote region.
- On-Demand Fetching: In the remote region, if a cache miss occurs, the replication engine intelligently fetches the up-to-date value from the storage engine. This “just-in-time” fetching ensures that the cache in the failover region warms up efficiently without requiring full data replication.
Adaptive Timeouts: The Smart Way to Handle Latency
Setting static timeouts for Redis operations can be a delicate balancing act. Too short, and requests might fail prematurely, burdening the database. Too long, and overall latency suffers. Uber’s solution? Adaptive timeouts.
CacheFront dynamically adjusts Redis operation timeouts based on real-time performance data. This intelligent approach ensures that:
- The vast majority of requests are served swiftly from the cache.
- Requests that exceed the dynamically adjusted timeout are promptly canceled and redirected to the database, preventing bottlenecks and optimizing both cache efficiency and database load.
The Impact: Unprecedented Performance Gains
The implementation of CacheFront has been a game-changer for Uber. This sophisticated caching solution, powered by Redis and meticulously engineered with features like CDC invalidation, adaptive timeouts, and smart failover handling, has yielded extraordinary results:
- Over 40 million reads per second from online storage.
- A staggering 75% reduction in P75 latency.
- An impressive 67% reduction in P99.9 latency.
Uber’s CacheFront stands as a testament to the power of intelligent caching and distributed systems design. By centralizing caching, ensuring data consistency, and proactively addressing operational challenges, Uber has not only delivered a superior user experience but also achieved remarkable operational efficiency and cost savings. It’s a prime example of how strategic investment in infrastructure can drive significant business impact in a high-scale environment.
To learn more about cloud computing and the caching guide, visit LogicHook and enroll today!
Also read: How CI/CD Pipelines work
